警視庁の「犯罪・交通事象・警備事象の予測におけるICT活用の在り方に関する有識者研究会」は、昨年取りまとめた提言書の中で、ICTを活用した科学的根拠に基づく予測情報により、不法事案の未然防止に向けた高度な警察活動の展開が可能となるという考えを示した。この提言書の中で、犯罪予測に関する国内の事例として紹介されたのがSingular Perturbations社の犯罪予測アプリケーションである。海外では既にオープンデータ等を活用した犯罪予測システムの導入が始まっているが、同社は独自のAIを組み込むことにより、他の既存のアプリケーションで使われるアルゴリズムを超える予測精度を達成した。独自AIの開発の経緯、及びオープンデータの活用の可能性と課題について、同社の創業者兼CEOであり、理論統計物理分野の研究者でもある梶田氏に、開発の経緯や特長、今後の展望を伺った。
1.犯罪発生予測アルゴリズムの着想
当社は、数学、統計学、及びGeospatial (空間情報)モデリングを用いて、時間、空間、社会データの予測分析を行なっています。
当社の犯罪予測アプリケーション「CRIME NABI」は、独自アルゴリズムのAIを標準的なAIに組み合わせたもので、2018年度に国立研究開発法人情報通信研究機構の高度通信・放送研究開発委託研究の「データ連携・利活用による地域課題解決のための実証型研究開発」の1つとして採択されました。この実証研究では、警察庁が2019年度から公開予定の犯罪データを用いて、いつ・どこで未来の犯罪が発生するかを予測する技術を確立し、モバイル及びウェブ上のアプリケーションを開発する予定です。
犯罪発生予測アルゴリズムの着想は、私が夫の赴任先であるイタリアに在住中していたときに、何度かスリの被害に遭ったことが直接的なきっかけです。イタリアでは、日曜日の午後は地元の住民は教会に行ったり、家族と過ごしたりします。そのため、この時間帯に街を出歩くのはたいてい旅行者だと分かってしまい、スリに狙われやすいのだということを、被害に遭った後で知ったのです。
もともと私は統計物理学の研究者ですが、イタリアで就職できない期間に独学でアプリケーション開発を学習して、オープンデータと組み合わせて「ガソリン天気予報」や「よむコッカイ」(国会議事録アプリ)といったアプリを作成していました。そこでこのできごとをきっかけに、日本の都道府県警察のメーリングリストから軽犯罪情報が取得できることに着目し、2014年にiOSアプリ「パトロールマップ」を作成しました。これは、毎日更新される軽犯罪情報をマップに可視化する機能に追加して、地域で起きた犯罪事件を利用者がマップ上に書きこんで共有するというもので、『週刊アスキー』誌でも紹介していただきました。
そうするうちに手元にデータが蓄積されてきたので、2011年に公表されていた犯罪予測の論文を使って分析を始めたところ、自分自身で物理学を応用した独自のモデルを試行した結果、予測精度の高いアルゴリズムが生まれました。
2.犯罪発生予測アルゴリズムの特長とデータ活用方法
犯罪予測は、世界的に警察機関等が導入を進めています。一定の効果を上げている事例としては、米国でロスアンゼルス市警等が導入したPredpol(※1)、シカゴ市警等のHunchLab(※2)があります。その他、英国ロンドンやドイツ・バイエルン州等において、独自のアプリケーションが導入されています。Predpolによる予測に基づいてパトロールを実施した結果、犯罪発生が20%程度減少したと言われています。
犯罪学の世界では、「近接反復被害」の法則が知られています。これは、犯罪者は一度犯行に成功すると、同じ現場の近くで犯行を繰り返すという考え方です。犯罪者が既に得た知識(環境とターゲットの行動等)を有効活用できるからです(図表1)。つまり、1つの犯罪が次の犯罪を誘発するカスケード現象と捉えることができます。したがって、過去に発生した犯罪の「種別」、「発生時間」、「発生場所」を基礎情報として、未来の犯罪が発生する可能性が高い時期とエリアを予測することが可能です。この考え方を数理モデル化したものは、Self-Exciting Point Process(SEPP) modelと呼ばれています。
図表1 近接反復被害の法則
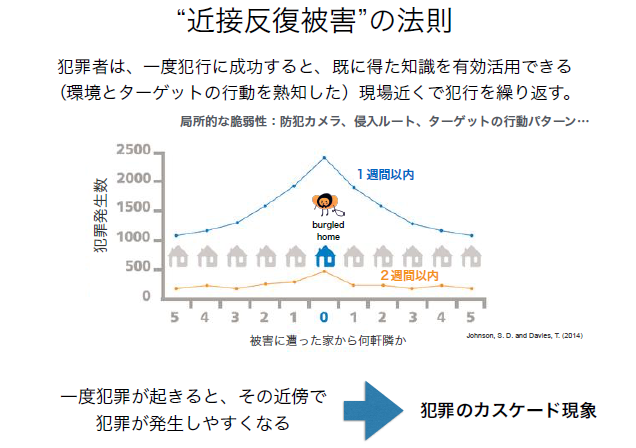
(出典)Johnson, S. D. and Davies, T.(2014)を基に梶田氏作成
当社が考案したData-driven Green's function(DDGF) アルゴリズムは、SEPPモデルを基にしつつ、機械学習の特徴と物理の特徴を併せ持っている点で、独自の手法となっています。物理では通常、基礎方程式があり、数学的に知りたい量を導くということをします。データは用いません。一方、機械学習では、仮定したモデルの中に決まっていないパラメータが含まれるため、これをデータから学習します。当社のDDGF法は、数学を用いつつデータからモデルパラメータを学習するハイブリッドな手法です。
実際に、警視庁が発行するメーリングリストの軽犯罪情報をもとに、東京のあるエリアを対象として犯罪発生を予測し、可視化したものが図表2です。ここでは、2015年7月2日にどこで犯罪発生の確率が高いかを予測するため、直前の100日間のデータを用いました。モノクロの印刷ではわかりにくいかもしれませんが、犯罪発生確率の高さを等高線のように表示したものです。上向きの矢印は、実際に2015年7月2日に犯罪が発生した場所を示しています。この図から、予測した犯罪発生密度が高いエリアで実際に犯罪が発生していることが、理解いただけると思います。
図表2 犯罪発生予測の視覚化

(出典)梶田氏作成
DDGFの予測精度を検証するため、シカゴの犯罪オープンデータを用いて、既存のアルゴリズムと比較したところ、10種の犯罪種別においていずれもDDGFが上回りました。また、そのうち2つの犯罪種別においては、1割以上高いスコアとなりました(図表3)。
図表3 DDGFの精度の検証結果
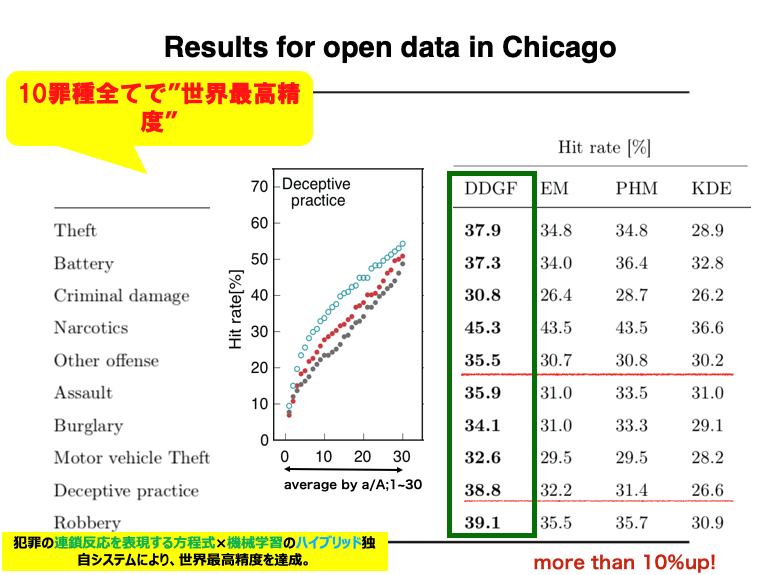
(出典)https://arxiv.org/abs/1704.00240を基に梶田氏作成
さらに、犯罪発生予測の精度が高いだけでなく、犯罪発生メカニズムも見て取ることができます。「近接反復被害」の法則に沿っていえば、住居侵入リスクは、1度被害が発生するとその1日、5日、9日後に上昇するというメカニズムが明らかになりました(図表4)。このメカニズムは、対象とする地域や期間によって異なります。
図表4 犯罪発生メカニズムの解明にも繋がる
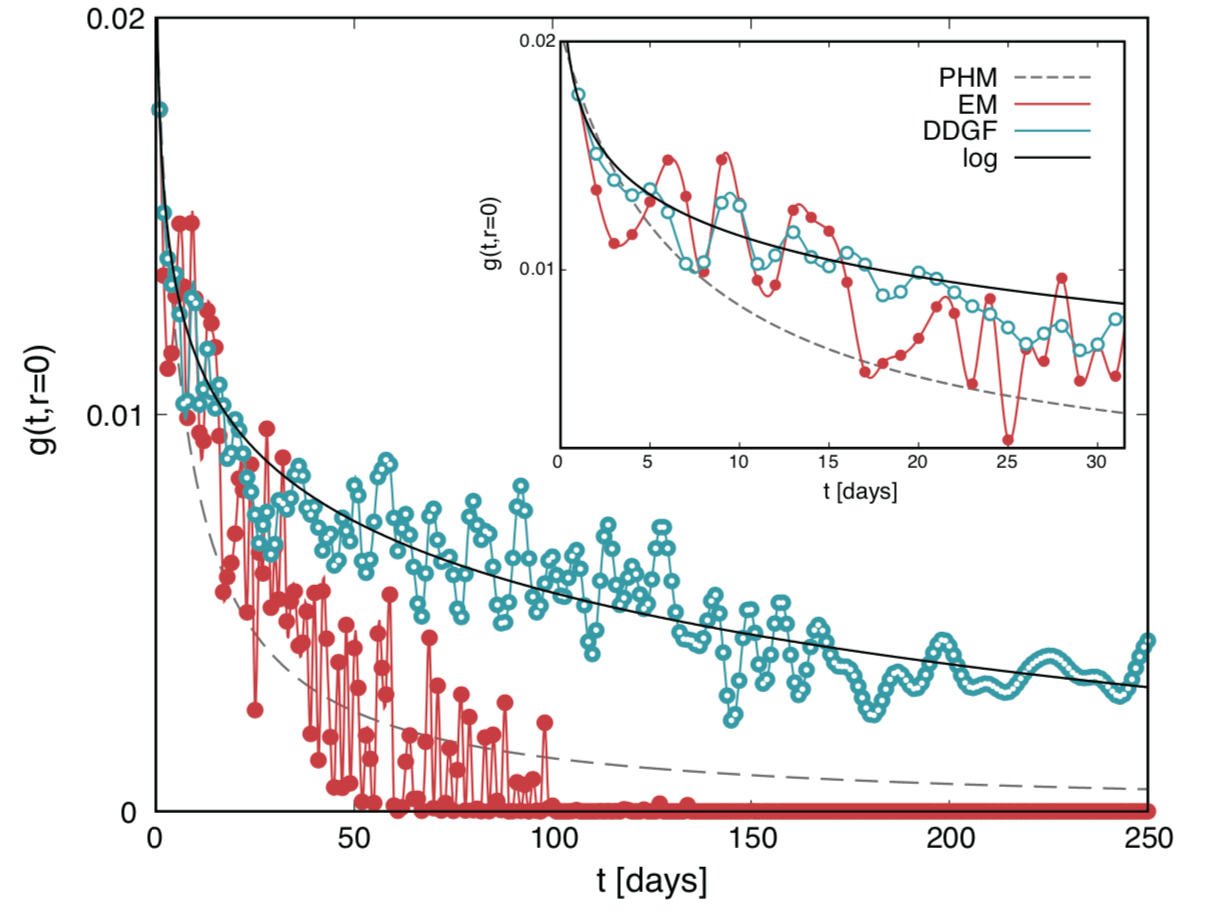
住居侵入リスクは1度被害が発生するとその1, 5, 9 日後に上がる
(出典)https://arxiv.org/abs/1704.00240を基に梶田氏作成
以上の説明では同種の犯罪の発生日という1つの変数の場合を例示しましたが、予測の対象を多変量に拡張することが可能です。例えば海外のデータであれば、銃関連の犯罪が殺人の発生に及ぼす影響を予測するといった、異なる犯罪種別にまたがる使い方です。
DDGF法の長所は、モデルを用いて予測する手法であるため、ディープラーニングの課題として指摘されるブラックボックスにはならないということです。モデルを使って予測の考え方を説明できること、入力するデータによって結果が変わるため、予測結果に対して解釈を加えて説明することができます。
※1 過去に発生した犯罪種別、場所、時間帯をもとに、犯罪発生率が高い要注意エリアを一辺が500フィート(約150m)の赤いボックスで地図上に表示する。警察官はこのエリアをアプリで確認し、パトロールする。
※2 1日内の時間や季節ごとの周期、天候や地域経済、過去の犯罪データなど様々な要因から犯罪の一定のパターンを見出す。デジタルマップ上に、次に犯罪が発生しそうな地点を表示する。
3.官公庁のデータを活用するにあたっての工夫
犯罪データのオープン化は、主な都市では米国のシカゴ、ニューヨーク、ポートランド、英国のロンドンで進められています。東京(警視庁)においてもオープン化は実施されていますが、現状は1ヶ月ごとの公開であり、残念ながらリアルタイムとは言い難い状況です。そのため、これまで当社は、犯罪の種別、日時、場所等の情報を、都道府県の警察が発行しているメーリングリストから該当するテキストを個別に拾い上げて、蓄積するしかありませんでした。この作業を2013年から続けています。こうした中、警察庁が2019年度から順次犯罪データをオープン化していくという方針を示しました。これを受けて、当社から当局へデータの密度や提供方法等について提案を行っています。また、東京都が「大東京防犯ネットワーク」というウェブサイトにおいて公開している情報も利用可能ですが、こちらにも月次の更新頻度を日次にしていただく等の要望を提示しています。
なお、犯罪発生予測アルゴリズムは軽犯罪も重犯罪も対象にできますが、オープン化されるデータは軽犯罪のみで、重犯罪のデータはオープンにされません。これは、プライバシーの問題のほか犯罪者による重犯罪への悪用を防ぐためでもあります。また、日本においては重犯罪の件数が少なく、予測精度が上がらないのが現状です。
4.犯罪発生予測の高度化に向けたデータ整備
犯罪発生予測にあたっては、上述した犯罪の「種別」、「発生時間」、「発生場所」という3つのデータ要素について、データ数が多く密度が高いほど精度が向上します。さらに、地域情報を変数に加えることが予測結果の詳細化につながります。例えば、人口や年代比率、商・工業地域等の地域情報を加えることで、予測を詳細化することが可能になります。
そのため、自治体には犯罪や前兆事案に関する学校情報や住民情報の提供をお願いしたいと考えています。警察と同様に、オープン化可能なデータとオープン化が困難なクローズドデータを区別していただくことにより、それぞれに用途を変えて活用することもできます。
また、データはcsv化するなど、機械可読形式とすることも要望中です。例えば、画像等にデータが埋め込まれていて、カーソルを乗せるとデータが浮かぶ見せ方がありますが、統計データとして用いるためには1つひとつのデータを抜き出す必要があり、データの収集自体に大変な労力がかかってしまいます。
日本におけるクローズデータを活用した犯罪予測の活用は、2016年10月開始の京都府警のシステム導入、2018年夏開始の神奈川県警の実証研究の例がありますが、今後、よりその活用が進んでいくことが期待されています。前述した諸外国に比べ、日本は現時点で、犯罪データの活用に関してはオープンデータ、クローズデータともにまだまだ周回遅れと言わざるを得ません。それでもオープンデータ化の取り組みは徐々に進んでいるので、関係機関に対して活用の可能性と要望を伝えているところです。使いやすいデータが全国でオープン化されることを期待しています。
5.今後の展望
スタンフォード大学の報告書『ARTIFICIAL INTELLIGENCE AND LIFE IN 2030』では、2030年までに北米の都市は「predictive policing」(予測的な警察活動)に大きく依存するようになるだろうと予測しています。しかし、犯罪発生予測は一種のセーフティネットであり、当社においてもビジネス化はまだこれからという段階です。まずは、2020年に向けてウェブとモバイルで市民向けのアプリケーションを開発する予定です。
警察活動や地域のパトロールのために予測情報を提供するだけでなく、住民向けのモバイルアプリとして、犯罪発生予測をもとに子どもの帰り道を変更するなどの用途を想定しています。こうしたサービスの展開にあたっては、自治体や通信事業者と連携したいと考えています。犯罪発生予測はこれまで日本になかった市場を創出する試みであり、また研究成果を社会に還元できる機会でもあるのです。
自然科学に比べて、社会データ分析では、データによりその結果が大きく変わることがあります。社会データをサイエンスの土俵に載せるには、再現性が非常に重要です。オープンデータがあることで、他の研究者による検証が可能となり、様々な背景の研究者が社会データ分析に参入することができるようになります。私自身も統計物理が専門である中、犯罪予測アルゴリズム開発の機会を与えてくれたのはオープンデータの存在でした。オープンデータがあることで、新しい技術が生まれ、新しいサービスとなって公益に戻るという循環が、より進めば、豊かな未来を作って行けるはずです。そうした取り組みに、私も微力ながら参加し、楽しい未来を作っていきたいと思っています。
|
梶田 真実(かじた まみ) 株式会社Singular Perturbations代表取締役、東京大学空間情報科学研究センター客員研究員。 2010年3月東京大学大学院(博士)、専門は統計物理(理論)。大阪大学・名古屋大学 学振特別研究員(PD)、イタリア滞在中にiOSアプリ開発、ベンチャー企業執行役員を経て2017年より現職。 |

